آمار زیستی علم مطالعه و عدم قطعیت دادههای زیستی می باشد. در آمار زیستی، دادههای جمع آوری شده از علوم زیستی اعم از زیستشناسی، پزشکی، میکروبیولوژی، شیمی و بسیاری از علوم پایه دیگر جمعآوری و مورد تجزیه و تحلیل قرار میگیرد. در این مبحث به مفاهیم پایه آمار زیستی و مثال های ساده آن در نرم افزار زبان برنامه نویسی R و رابط گرافیگی RStudio پرداخته شده است.
شاخصهای اصلی آمار زیستی
برای تجزیه و تحلیل این دادههای علوم زیستی از دو روش توصیفی و استنباطی استفاده میشود. آمار توصیفی به بررسی دادههای به دست آمده از آزمایش میپردازد و دارای شاخصهایی هستند که برای تعیین میزان تمرکز یا تفرّق دادهها از آنها استفاده میشود. این شاخصها شامل دو بخش مهم شاخصهای مرکزی (هیستوگرام، میانگین، میانه و مد) و شاخصهای پراکندگی (واریانس و انحراف معیار) میباشد.
مقدار متوسط دادههای اندازهگیری شده، میانگین (Average) و دادهای که پنجاه درصد دادهها از آنها کمتر یا بیشتر هستند میانه (Median) نامیده میشود.
میانه در واقع نقطه وسط دادهها را مشخص میکند.
شاخصهای پراکندگی شامل برد (Range statistics)، واریانس (Variance)، انحراف استاندارد (Standard deviation) و خطای استاندارد (Standard error) است.
اختلاف بین بیشترین و کمترین مقدار مشاهده در دادهها برد نامیده میشود.
واریانس شاخصی است که میزان پراکندگی دادهها را حول میانگین نشان میدهد.
انحراف استاندارد جذر واریانس است و یکی از شاخصهای مهم آزمونهای آماری برای بررسی پراکندگی دادهها میباشد.
خطای استاندارد برای اندازهگیری و محاسبه میزان نزدیکی میانگین نمونههای برگرفته از یک جامعه به میانگین کل جامعه استفاده میشود.
نمونه اسکریپت در نرم افزار R و رابط گرافیگی RStudio
Example
age=c(1, 3, 5, 2, 11, 9, 3, 9, 12, 3)
weight=c(4.4, 5.3, 7.2, 5.2, 8.5, 7.3, 6.0, 10.4, 10.2, 6.1)
mean(weight)
sd(weight)
cor(age,weight)
plot(age,weight)
مفهوم جامعه و نمونه در آمار زیستی
برای بررسی دادهها در علوم زیستی دو اصطلاح جامعه شامل تمام واحدهای موجود در تحقیق و نمونه شامل بخشی از افراد جامعه در نظر گرفته میشود. بررسیهای آماری در علوم زیستی نیازمند توصیفی از خصوصیات و ویژگیهای جامعه و نمونه مورد نظر میباشد که به آن متغیر یا صفات قابل اندازهگیری گفته میشود. متغیرها تغییرپذیر هستند و به دو دسته متغیرهای گسسته و پیوسته تقسیمبندی میشود. معمولا متغیرهای گسسته با نمودار میلهای و متغیرهای پیوسته با هیستوگرام نمایش داده میشود. یک ویژگی و مزیت مهم زبان برنامه نویسی R، تصویرسازی یا همان رسم نمودارها برای داده های گسسته و پیوسته میباشد. در زبان R و رابط گرافیگی RStudio به راحتی میتوان با خواندن داده های جامعه و نمونه، آن ها را در قالب نمودارهای مختلف و زیبا نمایش داده تا به یک درک تحلیلی سریع و قابل استناد دسترسی پیدا کند.
در نرم افزار زبان برنامه نویسی R و رابط گرافیگی RStudio بستههای (Packages) مختلفی برای ارائه نمودارهای مختلف وجود دارد که با نصب هر یک از این بسته ها می توان دادههای عددی خود را در قالب نمودارهای زیبا نشان داد. از جمله نمودارهای قابل رسم در نرم افزار زبان برنامه نویسی R و رابط گرافیگی RStudio نمودار دایرهای Pie Chart، نمودار خطی Line Chart، نمودار میلهای یا ستونی Bar Chart، نمودار هیستوگرام Histogram Chart، نمودار پراکندگی Scatter Chart میباشد.
مفهوم آزمون فرض در آمار علوم زیستی
برای درستی ادعای محققین، انجام آزمون فرض ضروری است و از آن مهمتر تشخیص آزمون مناسب با توجه به مساله محقق و نوع دادههای آنهاست. آزمونهای آماری در علوم زیستی به دو دسته آزمونهای پارامتری و ناپارامتری تقسیم میشوند. اگر دادههای موجود دارای توزیع نرمال باشند از آزمونهای پارامتری و در غیر این صورت از آزمون ناپارامتری استفاده میشود. بنابراین پس از تشخیص نوع دادهها (کمی یا کیفی بودن آنها) مهمترین کار، بررسی نرمال بودن یا نبودن دادهها میباشد و برای این امر از آزمون نیکویی برازش (Goodness of fit test) استفاده میشود.
فرضیات در تحقیق به گونه ای در نظر گرفته می شود که بتوان روشهای آماری را بررسی کرد.
آزمونها دارای فرض صفر و فرض مقابل است که باتوجه به نوع مساله تعیین میشود.
فرض صفر به طور کلی نشان دهنده برابری یا عدم وجود رابطه بین پدیده های اندازهگیری شده و عدم وجود ارتباط بین گروههای مختلف است.
فرض مقابل نقطه مقابل فرض صفر است و همواره مخالف آن است.
برای نتیجه گیری در مورد قبول یا رد یک آزمون فرض بر اساس پراستفاده ترین معیار، سطح معنیداری و مقدار احتمال در نظر گرفته میشود که با P-value نشان داده میشود.
اگر مقدار احتمال بیشتر از سطح خطای تعیین شده باشد فرض صفر قبول و فرض مقابل رد خواهد شد. در غیر اینصورت فرض صفر رد و فرض مقابل مورد قبول قرار خواهد گرفت.
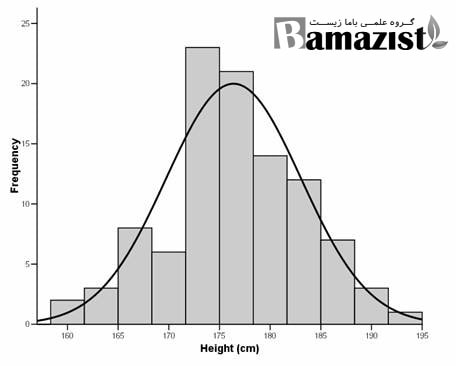
مفهوم توزیع نرمال یا گوسین یا نمودار زنگولهای در آمار زیستی
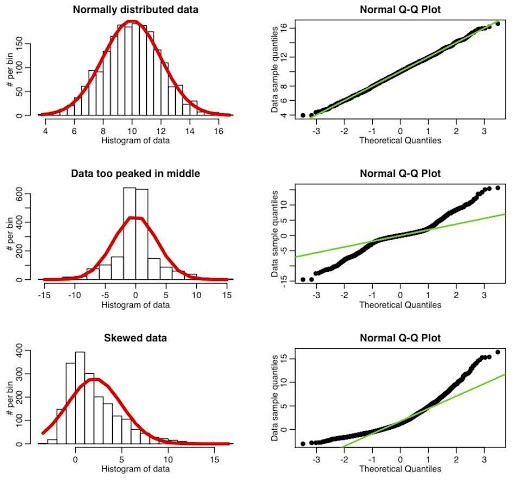
این توزیع از مهمترین توزیعهای آماری است که با استفاده از آن بسیاری از پدیدههای طبیعی مدلسازی میشود. در توزیع نرمال احتمال زیادی وجود دارد که توزیع اعداد نسبت به اعداد کمتر و اعداد بیشتر در میانگین اعداد جامعه قرار گیرد. توزیع نرمال با دو پارامتر اصلی میانگین و واریانس نمایش داده میشود و نشان میدهد که اگر از یک جامعه آماری نمونهگیری شود بیشتر دادههای به دست آمده حول محور میانگین میباشد و به این ترتیب نمودار زنگولهای تشکیل میشود و به این معنی است که بیشتر مقادیر دادههای به دست آمده نزدیک میانگین میباشد. خیلی از الگوریتمهای یادگیری ماشین با فرض نرمال بودن دادهها کار میکنند. یعنی دادههای وارد شده به نرم افزار باید حتما توزیع نرمالی داشته باشند. به همین دلیل یکی از مهمترین مراحل پردازش دادهها بررسی نرمالیته دادهها میباشد.
دو روش کلی در بررسی نرمال بودن دادهها وجود دارد،
روش اول مصورسازی و استفاده از هیستوگرام و نمودار Q-Qplot است. در هیستوگرام با استفاده از فراوانی متغیرها میتوان تعداد آنها را مشخص کرد. در نمودار Q-Qplot، انحراف معیار توزیع نرمال کمتر از یک حد مشخص شده میباشد.
روش دوم استفاده از آزمونهای آماری شامل شاپیرو-ویلک و کلموگروف-سیمورنوف و جارکو-برا میباشد. هیچگونه پیش فرضی برای استفاده از این آزمونها وجود ندارد و برای هر مجموعه میتوان این آزمونها را انجام داد.
خدمات گروه علمی بامازیست
جهت هرگونه مشاوره و راهنمایی در ارتباط با دستورات لازم برای اندازه گیری شاخص های مرکزی و پراکندگی در نرم افزار زبان برنامه نویسی R و رابط گرافیگی RStudio می توانید از مقالات گروه علمی بامازیست بهره بگیرید.